How I build an automated workflow designed to extract specific data from web pages, organize it in a Google Sheet, distribute the sheet, generate an article based on the data using Gemini, and finally publish the article to WordPress.
Here are the required steps:
- Source Google Sheet Connection and Aspect Identification:
- Establish a connection to a specified Google Sheet.
- Read the data from a designated table within this sheet.
- Identify the list of “defined Aspects” from the first column. The second column (“values”) is expected to be initially empty and will serve as the target for extracted data.
- URL List Import and Data Extraction:
- Accept a list of URLs as input sources for data scraping.
- For each URL in the provided list, navigate to the web page.
- Implement web scraping logic to locate and extract the numerical “values” corresponding to each of the “defined Aspects” identified in Step 1. This step requires robust parsing to handle variations in website structure.
- New Google Sheet Creation and Population:
- Create a new Google Sheet document.
- Structure this new sheet with the same two-column format as the source sheet: “defined Aspects” and “values”.
- Populate the “defined Aspects” column with the list obtained from the source sheet.
- Fill the “values” column with the corresponding numerical data extracted from the URLs in Step 2.
- Google Sheet Upload and Email Distribution:
- Upload the newly created and populated Google Sheet to Google Drive (or a specified location within Google Sheets).
- Concurrently, send an email to a predefined email address. The email should include the new Google Sheet either as an attachment or with a link to the uploaded document.
- Dynamic Prompt Generation and Article Creation (using Gemini):
- Construct a dynamic prompt for the Gemini model. This prompt will incorporate the “defined Aspects” and their extracted “values” from the new Google Sheet.
- Utilize the Gemini API with the generated prompt to create an article. The article’s content will be directly influenced by the extracted data, allowing for data-driven narratives or analyses.
- WordPress Article Publication:
- Connect to the target WordPress website using the WordPress API.
- Publish the article generated by Gemini (in Step 5) to the WordPress site. This includes setting the article title, content, and potentially other metadata like categories or tags.
This workflow requires integration with several services/Functions (Google Sheets, web scraping, email service, Gemini API, WordPress ) and (((Robust error handling at each step to ensure the process completes successfully))).
Your fast response will be appreciated.
This is a fantastic, comprehensive workflow, and yes, AgenticFlow is designed to handle exactly this kind of multi-step, multi-integration, AI-driven automation. Let’s break down how you’d build it:
Here’s How You Can Build This Workflow in AgenticFlow:
- Source Google Sheet Connection & Aspect Identification:
- Node: Google Sheets MCP (-> LInk: AgenticFlow - Automate Your Marketing Workflows)
- Action: Use an action like “Get Spreadsheet Values” or “Get Rows” (depending on the specific MCP actions available) to read your source sheet.
- Logic: You’ll likely get the data as an array of arrays or array of objects. You can use a simple “Code” node (JavaScript) or an LLM node to process this output and extract the list of “defined Aspects” from the first column. Store this list in a workflow variable.
URL List Import and Data Extraction:
- Input: You can provide the list of URLs as a direct input to the workflow (e.g., a text input when you run it, or from another Table dataset).
- Looping (Conceptual) - For each URL:
- Node: Web Scraping node (built-in) or Apify MCP (AgenticFlow - Automate Your Marketing Workflows) for more robust scraping of varied site structures.
- Action (Scraping): Scrape the content of the current URL.
- Node: LLM node (e.g., Gemini via BYOK in Settings > Connections, or our built-in Gemini-Flash).
- Action (Extraction):
Input: The scraped web page content AND your list of “defined Aspects” (from step 1).
Prompt: “From the following web page content: {{scraped_content}}, extract the numerical values for each of these aspects: {{list_of_defined_aspects}}. Return the results as a JSON object where keys are the aspects and values are the extracted numbers. If an aspect is not found, use null as its value.”
Output: A JSON object with aspects and their extracted values for that specific URL.
Note on Looping: True iteration over a list within a single workflow run is an area we’re enhancing. Currently, you might handle this by triggering the “scrape & extract” part of the workflow for each URL individually via API, or process a batch if the number of URLs is small and manageable in one LLM call. For many URLs, an Agent orchestrating these calls might be more effective until loop nodes are fully mature.
- New Google Sheet Creation and Population:
- Node: Google Sheets MCP.
- Action (Create Sheet): Use an action like “Create Spreadsheet” to make a new Google Sheet. Get its ID.
- Action (Populate Headers): Use “Update Cells” or “Append Row” to write “defined Aspects” and “values” as headers in the new sheet.
- Action (Populate Data): As you get the JSON output from step 2 for each URL, you’d reformat it (if needed, e.g., with a Code node or LLM to turn the JSON object into an array of [aspect, value] pairs) and use “Append Rows” to add the defined aspects and their corresponding extracted values to the new sheet. This would also likely be part of a loop or batched processing.
4. Google Sheet Upload and Email Distribution:
- Google Drive Upload (if needed): The Google Sheets MCP creates the sheet directly in Drive. You’ll have its URL from the “Create Spreadsheet” action or can construct it.
- Node: Gmail MCP (AgenticFlow - Automate Your Marketing Workflows) or the built-in “Send Email” node.
- Action: Send an email to your predefined address.
- Content: Include a message and the link to the newly created Google Sheet (obtained from the Google Sheets MCP output). You can also attach the file if you first use a Google Drive MCP action to download it, then attach it to the email, but linking is usually simpler.
5. Dynamic Prompt Generation and Article Creation (using Gemini):
- Node: LLM node (configured to use your Gemini API Key via Connections, or our built-in Gemini-Flash).
- Input Data: The data from your newly populated Google Sheet (you might re-read it using the Google Sheets MCP to ensure you have the final, complete dataset).
- Action (Prompt Construction): You can either feed the entire dataset as context or use a “Code” node/another LLM node to format the “defined Aspects” and “values” into a structured part of your Gemini prompt. Example segment: “Here is the data for your article: Aspect1: Value1, Aspect2: Value2…”
- Prompt (Gemini): “Based on the following data: [structured_data_from_sheet], write an article that [explain the goal of the article, e.g., ‘analyzes these trends’, ‘provides a narrative about these findings’, etc.].”
- Output: The generated article text.
6. WordPress Article Publication:
- Node: WordPress MCP (AgenticFlow - Automate Your Marketing Workflows).
- Action: Use the “Create Post” action.
Inputs:
- title: Generate a title (either from the Gemini article or a separate LLM step).
- content: The article content from Gemini (Step 5).
- status: ‘publish’ (or ‘draft’).
Optionally, categories, tags if the MCP action supports them or if you construct the appropriate API payload.
7. Error Handling:
- Workflow Level: AgenticFlow workflows will show an error at the step where an issue occurs. You can inspect the inputs/outputs of each node to debug.
- Robustness: For scraping, using Apify is recommended as it handles many anti-scraping measures. For API calls (Gemini, WordPress), ensure your prompts and payloads are correctly formatted. You can add conditional logic (e.g., if an LLM extraction returns null, try a different prompt or log an error) as our conditional routing features improve. For now, for very complex error handling, you might use an Agent to manage retries or alternative paths based on step success/failure.
This is a sophisticated but definitely achievable workflow with AgenticFlow! Given the multiple integrations and potential for iteration logic, starting with a higher tier (like Tier 3 or 4 for the increased credits and priority support) would be beneficial to help you get it fine-tuned.
Let me know if you’d like a pointer on a specific part of this!
Best,
Wendy
Is not cleare this section:
" WordPress Article Publication:
- Node: WordPress MCP ([AgenticFlow - Automate Your Marketing Workflows].
- Action: Use the “Create Post” action.
Inputs:
- title: Generate a title (either from the Gemini article or a separate LLM step).
- content: The article content from Gemini (Step 5).
- status: ‘publish’ (or ‘draft’)."
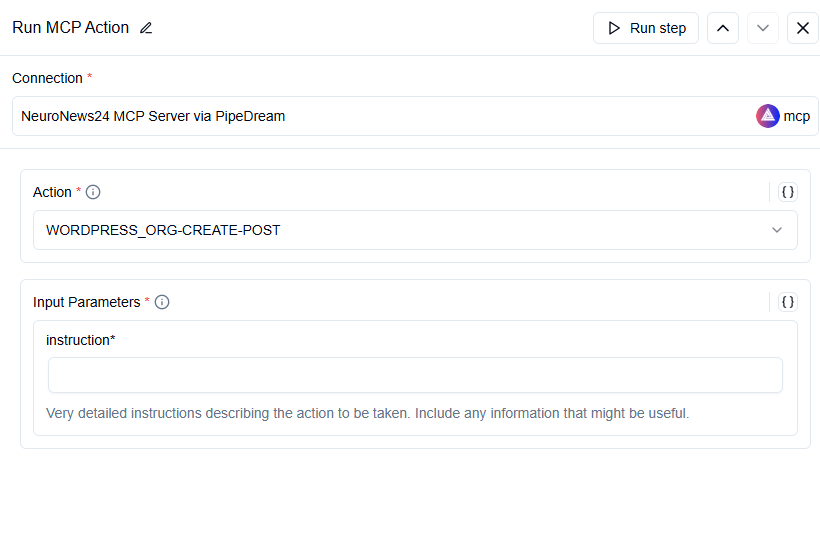
I tryed to run a Run MCP Action in my workflow but this was the error message:
{ “message”: “1 validation error for MCPRunActionInput\ninput_params\n Input should be a valid dictionary [type=dict_type, input_value=‘delivery.agentic...c57b5cd9e3ed6c0b9ce.png’, input_type=str]\n For further information visit errors.pydantic.dev/2.11/v/dict_type”, “code”: “ValidationError”, “details”: “1 validation error for MCPRunActionInput\ninput_params\n Input should be a valid dictionary type=dict_type, input_value='delivery.agentic...c57b5cd9e3ed6c0b9ce.png’, input_type=str]\n For further information visit errors.pydantic.dev/2.11/v/dict_type” }
How to fix it? No references I found in this community Forum or in FAQ.
What does the “instruction” section means? In which format?
Thank you for help me
Federico
I saw that Mia already replied to your message via email, but I wanted to follow up to clarify the issue more succinctly:
The error you’re encountering is due to input_params expecting a valid JSON dictionary, but it’s receiving a plain string instead (e.g. a direct URL). That’s what causes the validation error.
However, the core issue lies with Pipedream.
Pipedream’s current integration does not support managing WordPress posts, especially for self-hosted sites. Their auth0 setup doesn’t have the necessary permissions to create drafts or publish posts.
So even if your input_params were correctly formatted, the workflow would still fail — because Pipedream isn’t authorized to interact with your WordPress site that way.
If you’re comfortable configuring your backend, you can set up WordPress Application Passwords or JWT authentication, and then send content via the API Call node in AgenticFlow — that way, you bypass Pipedream entirely.
Best,
Wendy